Today, Sarah Wynn-Williams—the author of Careless People—is set to testify before Congress relating to whether Meta Platforms, Inc.’s (formerly Facebook) dealings with the Chinese Communist Party undermined U.S. national security.
Ms. Wynn-Williams spent six years at Facebook, where she climbed the ranks from a position that she convinced Meta to create to Director of Global Public Policy.
One of the more shocking revelations in Careless People—and there are many—is the disconnect between Meta’s actual business practices and its public representations.
This is a problem. When one of the largest advertising companies—and that is what Meta is at its core—misleads both the public and lawmakers about how it handles user data and what it does with it, this has real-world consequences.
Leading up to the hearing today, we’ve broken down some of Meta’s biggest omissions—and outright lies—concerning its data collection and use practices.
1. Meta Denies Emotion-Based Targeting
On May 1, 2017, The Australian got its hands on a presentation prepared by Meta for one of its advertisers, a top Australian bank. It claimed the presentation represented that Meta can detect, from photos, young people’s emotions, such as being “anxious” or “useless.” It also boasted it had “internal Facebook data” that can be used to detect “mood shifts” of young users.
Meta rebuffed these claims in a statement on April 30, 2017, calling the article “misleading” and claiming “Facebook does not offer tools to target people based on their emotional state.” It downplayed the article to a one-off instance where it “did not follow” its normal review process—whatever that is.
According to Ms. Wynn-Williams, however, Meta was actively advertising these capabilities. In fact, they had included these talking points in so many slide decks that Facebook internally struggled to figure out which one was leaked to the press.
Other public information would appear consistent with Ms. Wynn-Williams’s account.
For instance, up until 2021, Meta was running extensive face recognition technology on Facebook users and used that technology to provide AI-generated “descriptions” of the images. Meta ultimately paid $1.4 billion to resolve a lawsuit brought by the Texas Attorney General relating to this technology, which alleged Meta was collecting biometric data from certain users without consent.
Separately, documents shared by Frances Haugen, another Meta whistleblower, would reveal that Meta was aware since 2017 that its ad ranking algorithms—which rely on machine learning—would push content that triggered emotional responses because it was content users were more likely to engage with.
Part of the signals used in Meta’s ad ranking algorithm was whether users “liked” or responded with an “angry” emoji to content, which are actions consistent with their real-life emotions.
2. Meta Promises Data Privacy Controls & Data Deletion
Meta’s claims about its ad targeting capabilities—or lack thereof—would continue the following year.
In April 2018—in response to Cambridge Analytics—Mark Zuckerburg was grilled by Congress about how it receives and uses user data, as well as which controls are available for individuals to limit Meta’s use of that information. Mr. Zuckerberg outlined an action plan to stymie congressional fears, including the following promises:
- Zuckerberg promised that if anyone “improperly used data” that Meta was “going to ban them from [its] platform and tell everyone affected.”
- Zuckerberg repeatedly testified that there are “control[s]” made available to Facebook users that can prevent their data being used for ads.
- He confirmed non-Facebook users can utilize similar controls: “anyone can turn off and opt out of any data collection for ads, whether they use our service or not.”
- He also promised that if individuals “delete [their account]” that Meta gets “rid of all your information” which would bar Facebook and third parties from using that data.
Big promises. If only they were true.
There are several instances where Meta has not banned advertisers from using its services when they “misuse” data. For instance, an FTC investigation in June 2021 would reveal that a Meta advertiser—Flo Health, Inc.—was sharing users’ pregnancy status through the Facebook Pixel. Meta itself used this data for its own internal purposes.
Meta denied having knowledge that it received health data from Flo Health, Inc. (if you believe that), but it certainly did not “ban” Flo Health. Flo Health continues to have an advertising relationship with Meta according to Flo Health’s current privacy policy.
Zuckerberg’s promises about data controls are also half-truths, at best.
Consumers cannot fully control whether their data is used for ads because Meta itself cannot control this. According to leaked documents, even in 2021 Meta still lacked an “adequate level of control and explainability over how [its] systems use data.” This is because Meta’s systems were designed to be “open” precisely to enable data sharing, and all data feeds into an extensive “data lake” for which Meta has little to no visibility.

Thus, the leaked documents explain Meta cannot promise “we will not use X data for Y purpose”—because it simply lacks the means to actually implement that change. The same design issue prevents Meta from ensuring data is ever truly deleted and no longer used for advertisements—the exact opposite of what Mr. Zuckerberg stated to Congress.
Finally, some of Meta’s data collection tools are designed to bypass available privacy-preserving mechanisms altogether, undercutting Mr. Zuckerberg’s promise that both Facebook and Non-Facebook users can prevent unwanted data collection.
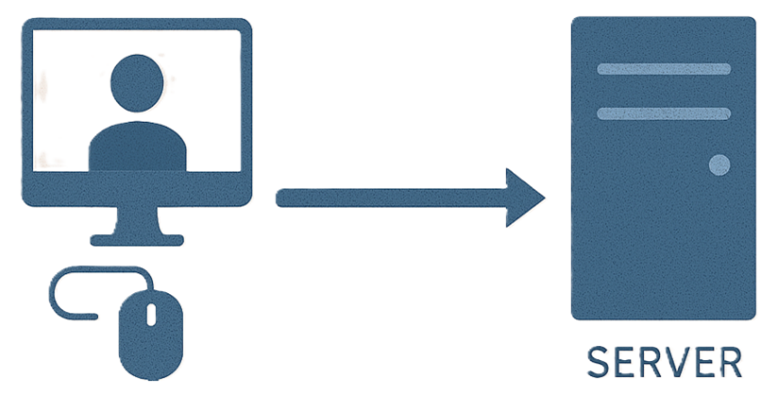
Take, for instance, Meta’s Conversions API (“CAPI”), a tool that allows website developers to send data directly to Meta through a server-to-server integration. Because CAPI bypasses the user’s browser, it cannot be blocked by typical privacy-preserving mechanisms (like Safari’s Intelligent Tracking Prevention) or by opting out of cookies. This kind of behind-the-scenes data sharing—largely invisible to users—is fundamentally at odds with Meta’s claim that users can “control” whether their data is collected or used.
Final Takeaway
The consequences of Meta’s half-truths, and outright misrepresentations, are profound. They don’t just shape how the public perceives Meta, they actively impede government oversight and regulation, and whether Meta is ultimately held accountable for its own actions.
Senator Blumenthal asked the right question back in 2021: “Facebook has asked us to trust it. But after [its prior] evasions . . . why should we?”
The answer: we should not.